Abstract
Effective content moderation systems require explicit classification criteria, yet online communities like subreddits often operate with diverse, implicit standards. This work introduces a novel approach to identify and extract these implicit criteria from historical moderation data using an interpretable architecture. We represent moderation criteria as score tables of lexical expressions associated with content removal, enabling systematic comparison across different communities.
Our experiments demonstrate that these extracted lexical patterns effectively replicate the performance of neural moderation models while providing transparent insights into decision-making processes. The resulting criteria matrix reveals significant variations in how seemingly shared norms are actually enforced, uncovering previously undocumented moderation patterns including community-specific tolerances for language, features for topical restrictions, and underlying subcategories of the toxic speech classification.
Key Contributions
- CriteriaMatrix Representation: A novel representation of moderation criteria as scores assigned to lexical expressions, providing unambiguous and verifiable insights into community-specific moderation patterns.
- Interpretable Architecture (PAT): Demonstrating how Partial Attention Transformer can effectively identify global moderation patterns by assigning well-calibrated scores to text spans while achieving performance comparable to ChatGPT.
- Revealing Hidden Patterns: Uncovering previously unrecognized characteristics of moderation practices across Reddit communities, including varying tolerances for similar content types and community-specific enforcement patterns.
Dataset
We used the Reddit moderation dataset containing 2.8 million comments removed by moderators from 100 top subreddits, collected over 10 months from May 2016 to March 2017. The dataset was augmented with unmoderated comments to construct balanced datasets across 97 subreddits, with training data ranging from 2,600 to 248,000 instances (median: 17,928).
Method Overview
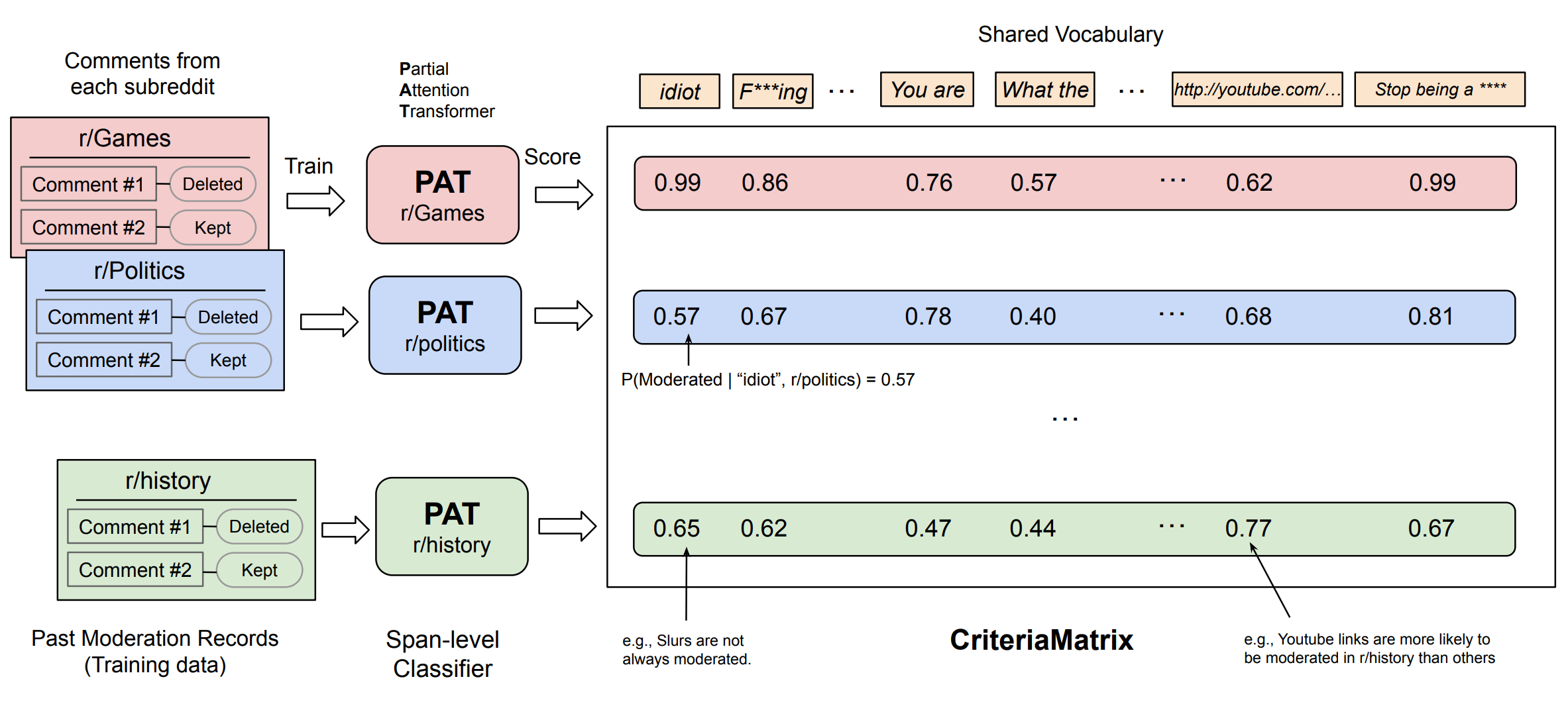
Figure 1: Overview of our approach for extracting implicit moderation criteria using Partial Attention Transformer (PAT) and constructing the CriteriaMatrix.
We conceptualize the challenge of understanding community-specific moderation as a vocabulary scoring problem. Our approach builds explicit, unambiguous representations of subreddit-specific moderation criteria by extracting and scoring phrasal expressions for each community.
Partial Attention Transformer (PAT)
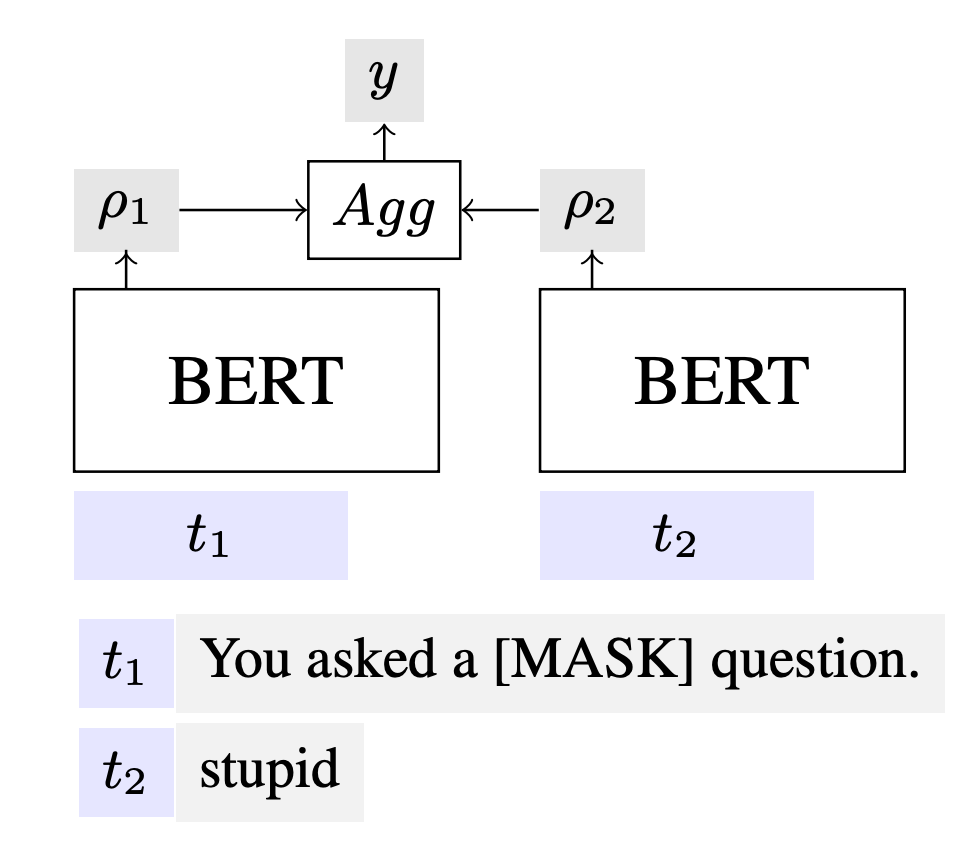
Figure 2. PAT training architecture.
We employ PAT, an interpretable architecture designed for model explanations in text classification tasks. The key strength of PAT lies in its ability to assign well-calibrated probability values to individual text spans missing context.
A comment text “You asked a stupid question” is partitioned into two sequences t1 and t2, which are
encoded by BERT. The model is supervised with final y label, while encouraging the model to generate
corresponding scores ρ1 and ρ2 for each sequences.
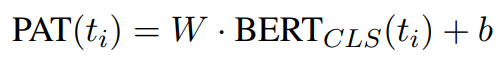
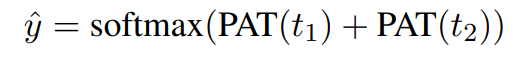
After training on full texts with moderation labels, PAT is applied at the vocabulary level to predict scores for lexical expressions, revealing which terms are highly indicative of moderation outcomes.
CriteriaMatrix Construction
For each of 60 subreddits, we train a PAT model and build a shared vocabulary of n-grams extracted from high-scoring text spans. Each PAT model then scores all terms in the vocabulary, creating a score matrix where element M[i,j] indicates the contribution of term j to moderation decisions in subreddit i.
Findings on Moderation Criteria
Analysis 1: Uncovering Hidden Community Rules
The CriteriaMatrix reveals hyper-specific rules.- r/fantasyfootball
- Official Rule: No individual threads specific to your team.
- Discovered Pattern: Phrases such as “thinking about starting” and “should I use” are strong indicators of team-specific questions.
- r/Games
- Official Rule: No off-topic posts.
- Discovered Pattern: Location names like “San Francisco” and “Utah” often signal off-topic content and trigger strict enforcement.
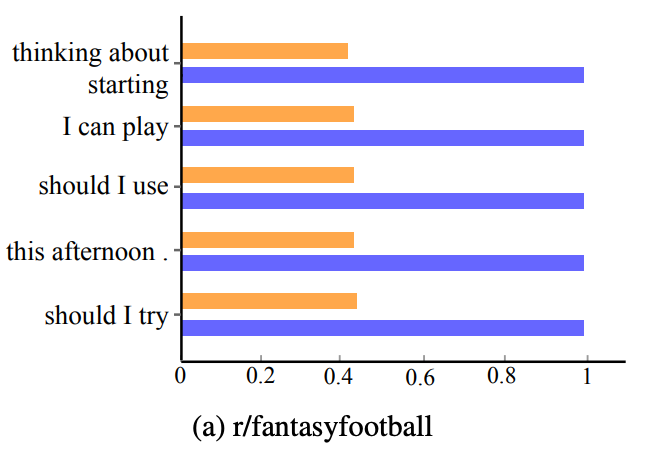
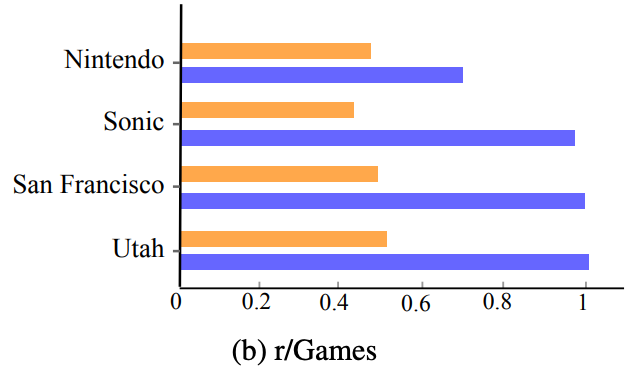
Figure 3: Representative terms with large score differences between subreddit-specific scores (blue) and average across subreddits (orange) for r/fantasyfootball and r/Games.
Analysis 2: The "Mod Mention" Rule Nobody Wrote Down
What CriteriaMatrix Found:
- The term "mod" scores 0.68 on average
- In 12 subreddits: scores > 0.90
- Our models learned: any mention of "mod" = likely removal
Reality Check with Synthetic Data:
- Generated 50 completely neutral "mod" comments
- 27% of classifiers flagged all 50 for removal
In original training data:
- 34% of subreddits actually remove >80% of "mod" mentions
- 16% of subreddits remove >90% of them
The models aren't wrong—the moderators really are that strict.
Human moderators enforce an implicit, draconian rule: discussing moderation itself is taboo, regardless of tone or intent.
Our classifiers simply learned to replicate human behavior.
Analysis 3: Different communities, different tolerance levels
The Method:
Created term vectors using moderation scores across all subreddits and applied k-means clustering (k=100) to group similar terms. Identified 9 distinct personal attack clusters.
The Spectrum Across Communities:
| Attack Type | Example Terms | Subreddit A | Subreddit B |
|---|---|---|---|
| Direct Intelligence Insults | "you are an idiot" | 0.99 | 0.77 |
| Second-Person Framing | "you," "you are" | 0.60 | 0.90 |
| Boundary-Crossing Advice | "get your," "let your" | 0.86 | 0.51 |
| Competence Undermining | "you have no idea" | 0.77 | 0.49 |
BibTeX
@article{kim2025decoding,
title={Decoding the Rule Book: Extracting Hidden Moderation Criteria from Reddit Communities},
author={Kim, Youngwoo and Beniwal, Himanshu and Johnson, Steven L and Hartvigsen, Thomas},
journal={arXiv preprint arXiv:2509.02926},
year={2025}
}